Omni6DPose: A Benchmark and Model for Universal 6D Object Pose Estimation and Tracking
ECCV 2024

Abstract
6D Object Pose Estimation is a critical yet challenging task in the field of computer vision, distinguished from more traditional 2D tasks by its lack of large-scale datasets. This scarcity hampers comprehensive evaluation of model performance and consequently, limits research development while also restricting the applicability of research across diverse domains due to the limited number of instances or categories available. To address these issues and facilitate progress in 6D object pose estimation, this paper introduces Omni6DPose, a substantial dataset featured by its diversity in object categories, large scale, and variety in object materials. Omni6DPose is divided into three main components: ROPE (Real 6D Object Pose Estimation Dataset), which includes 332K images annotated with over 1.5M annotations across 581 instances in 149 categories; SOPE (Simulated 6D Object Pose Estimation Dataset), consisting of 475K images created in a mixed reality setting with depth simulation, annotated with over 5M annotations across 4162 instances in the same 149 categories; and the manually aligned real scanned objects used in both ROPE and SOPE. Omni6DPose is inherently challenging due to the substantial variations and ambiguities. To address this challenge, we introduce GenPose++, an enhanced version of the state-of-the-art category-level pose estimation framework. GenPose++ incorporates two pivotal improvements: Semantic-aware feature extraction and Clustering-based aggregation, tailored specifically to the nuances of the Omni6DPose in question. Moreover, this paper provides a comprehensive benchmarking analysis to evaluate the performance of previous methods on this large-scale dataset in the realms of 6D object pose estimation and pose tracking.
Demo Videos
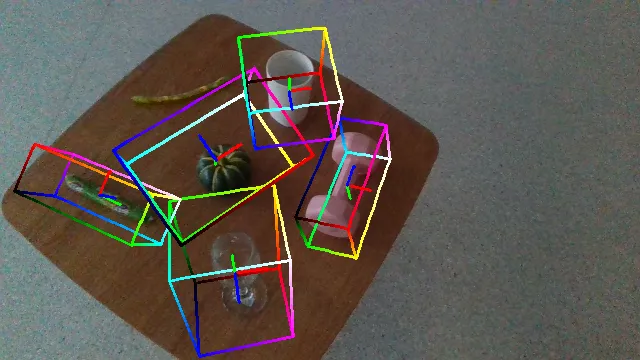
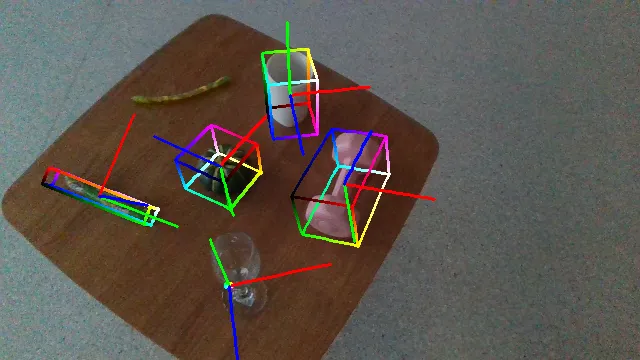
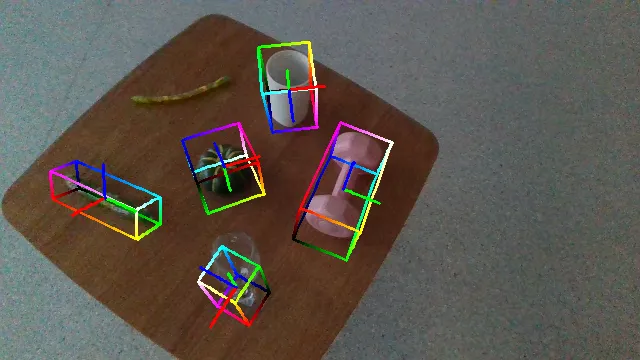
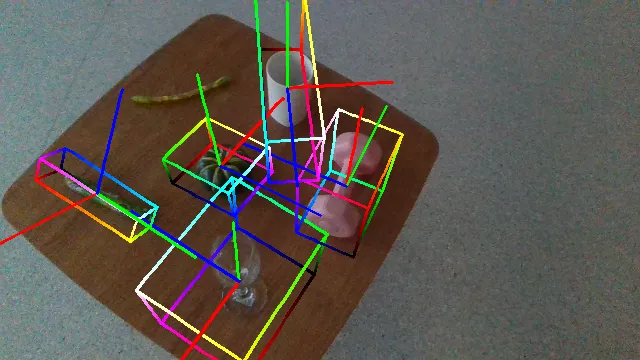
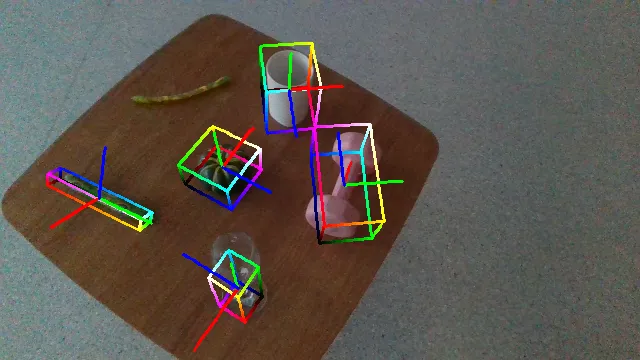
Here we demonstrate several videos of our ROPE datasets, annotated with ground truth object poses (as axes) and scales (as bounding box). Detailed data samples are illustrated in the following section.
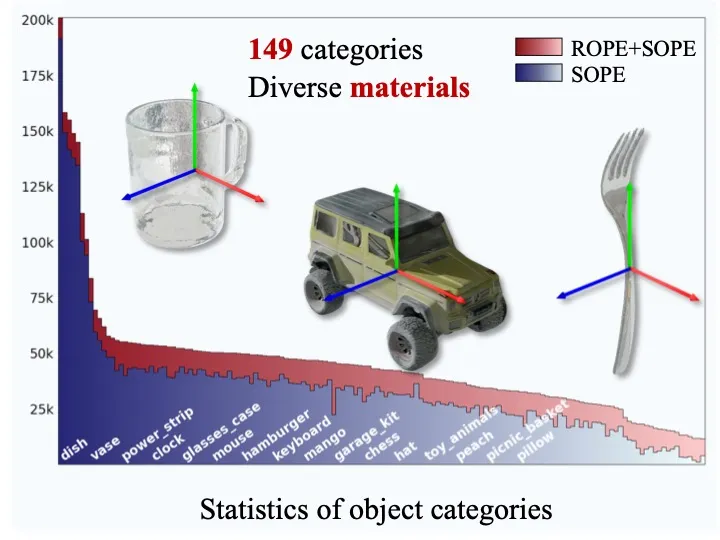
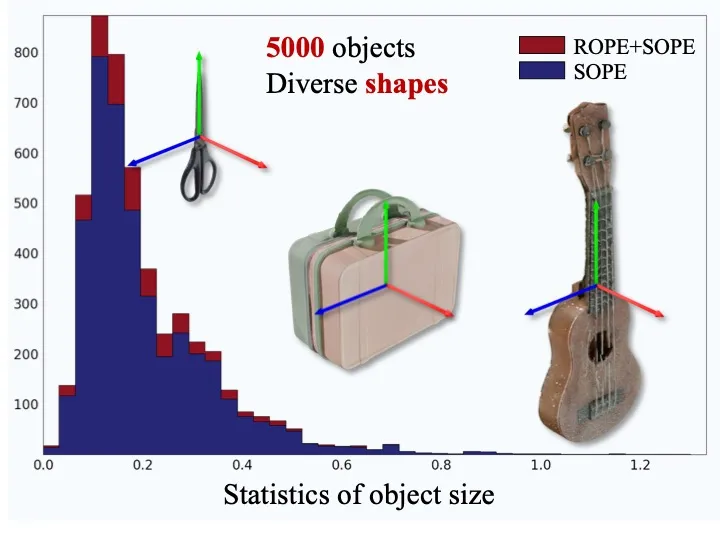
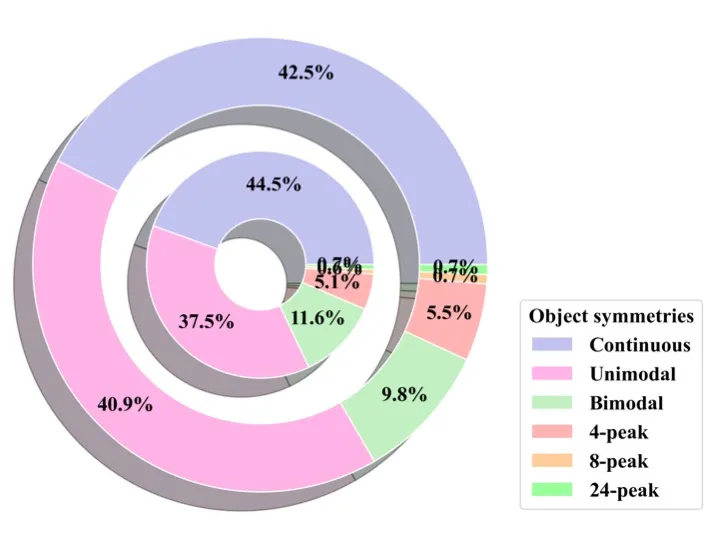
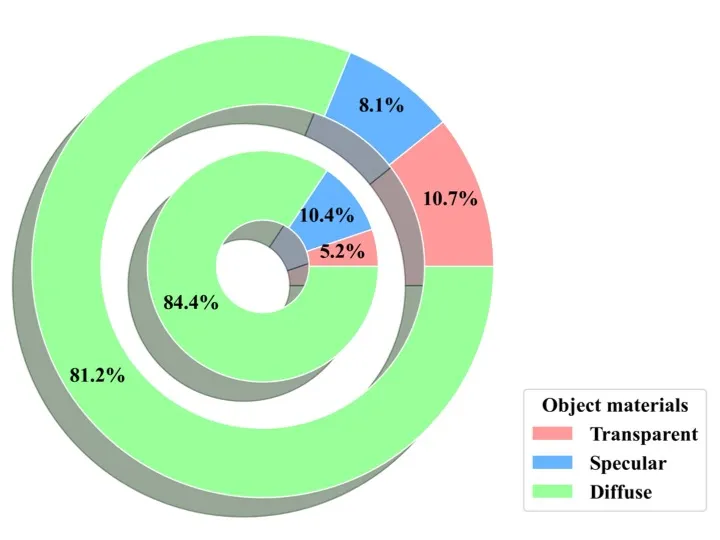
Datasets Statistics
Our datasets possess 149 categories, roughly 5k different objects with diverse materials and sizes. The following figures illustrate the statistics of object categories, sizes, symmetries, and materials in our datasets (inner rings denote ROPE statistics and outer rings denote SOPE statistics).
Pipelines and Interactive Visualization
For a detailed view of our datasets, we provide an interactive user interface for out SOPE dataset, ROPE dataset and a small subset of 3D object meshes. You can switch among the follow tabs to play with them.
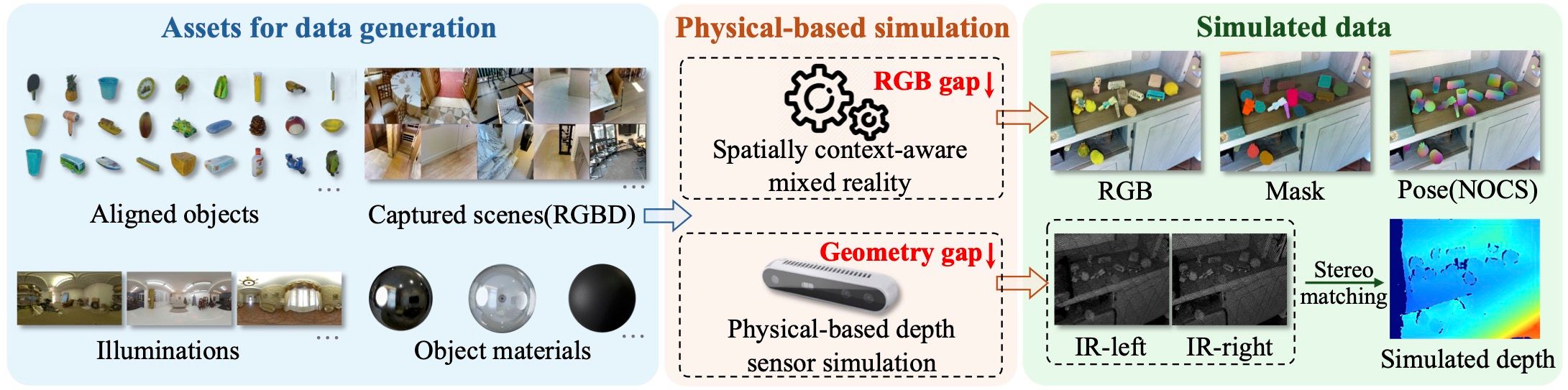
The above figure demonstrates the data collecting pipeline of our SOPE dataset. Here below are some sample data from it. You can drag the splitting slider towards left or right to alter the boundary of original image and the pose annotated image. On the other hand, the visualization of depth point clouds is also interactive, where you may change the viewpoint of camera, zoom in or zoom out.
Enhanced Pose Estimation: GenPose++
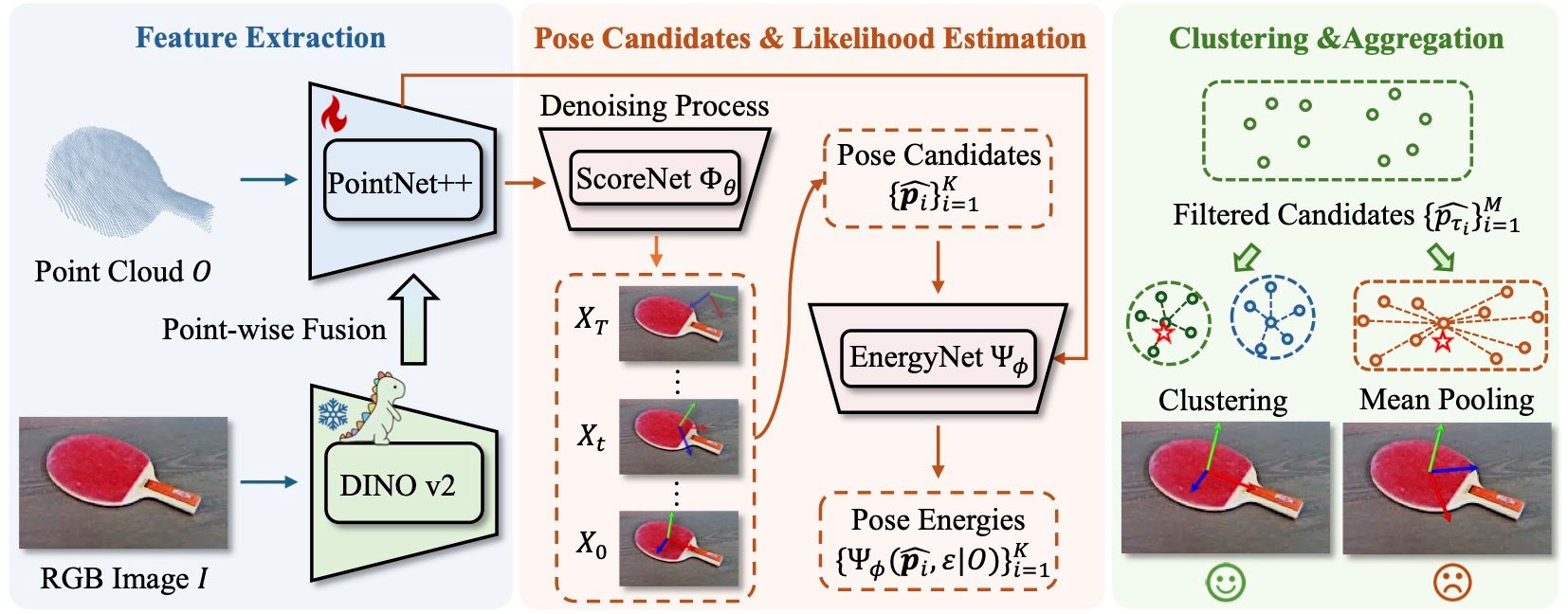
GenPose++ employs segmented point clouds and cropped RGB images as inputs, utilizing PointNet++ for extracting object geometric features. It employs a pre-trained 2D foundation backbone, DINO v2, to extract general semantic features. These features are then fused as the condition of a diffusion model to generate object pose candidates and their corresponding energy. Finally, clustering is applied to address the aggregation issues associated with the multimodal distribution of poses for objects exhibiting non-continuous symmetry, such as boxes, effectively resolving the pose estimation challenge.
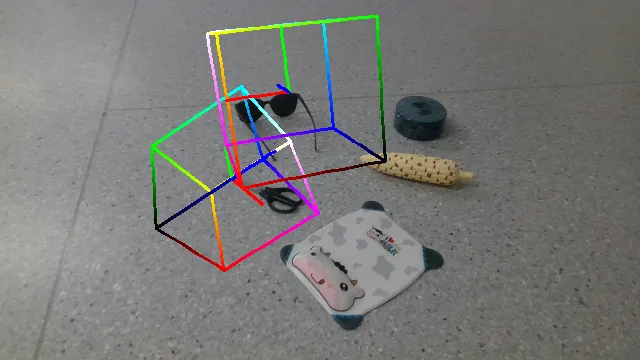
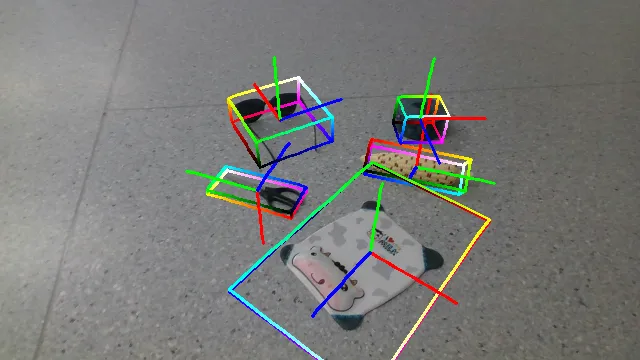
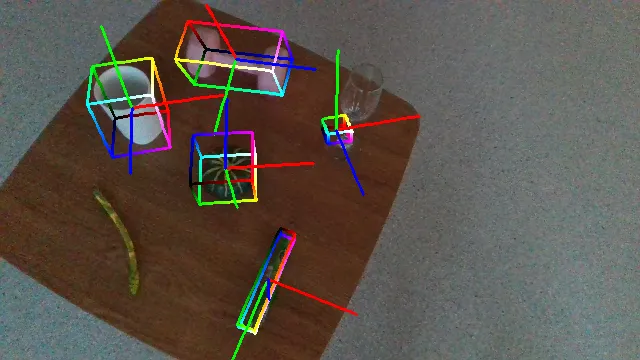
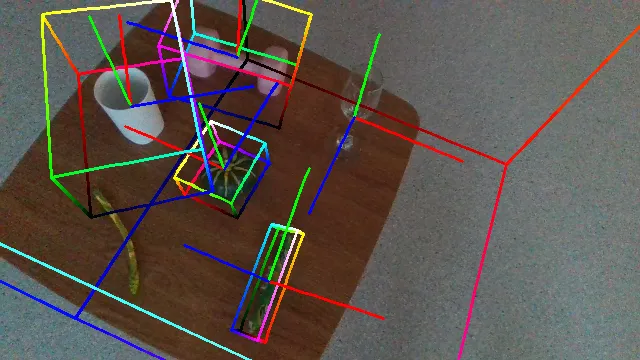
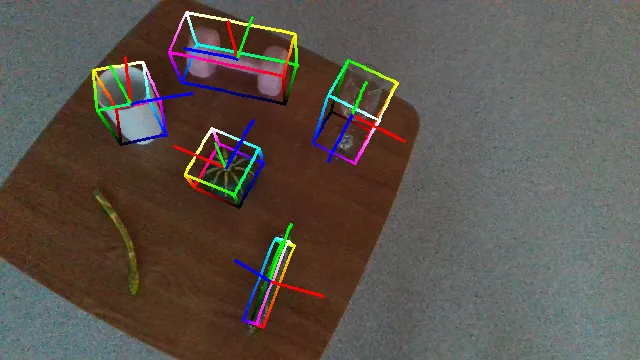
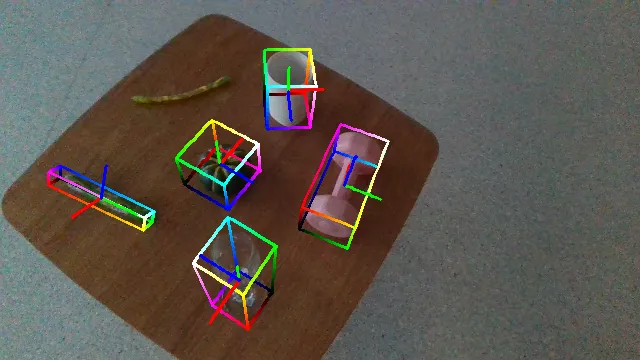
Qualitative Results and Comparison
The following videos demonstrate the qualitative results of GenPose++, corresponding to the groud truth annotated videos in the previous section respectively.
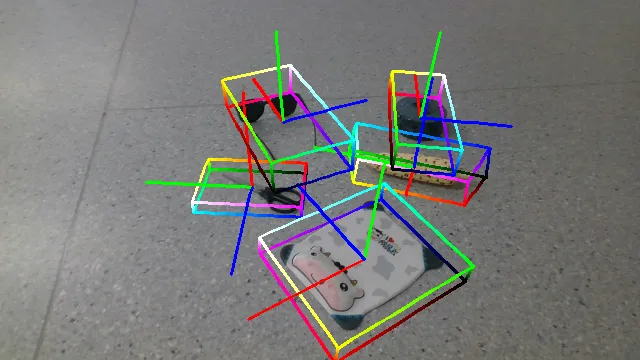
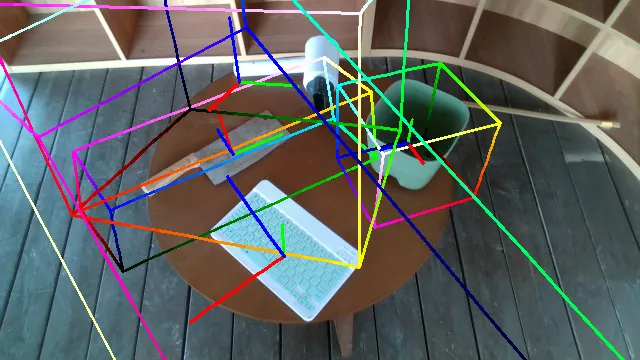
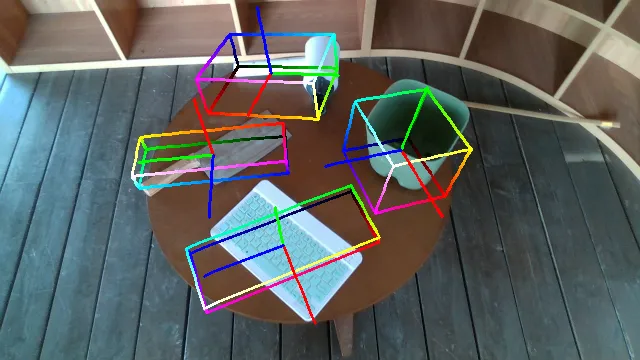
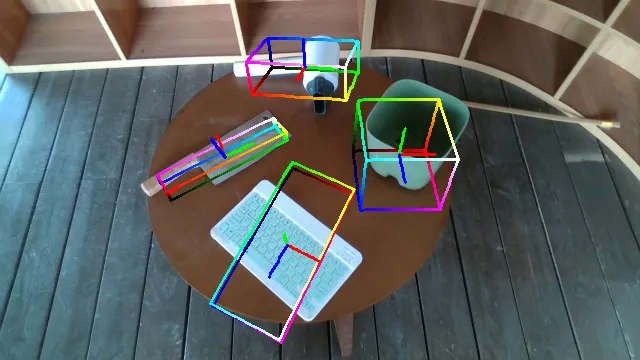
Here are some qualitative results comparing our methods with baselines. Columns from left to right are: ground truth, NOCS, SGPA, HS-Pose, IST-Net, GenPose and GenPose++, respectively.






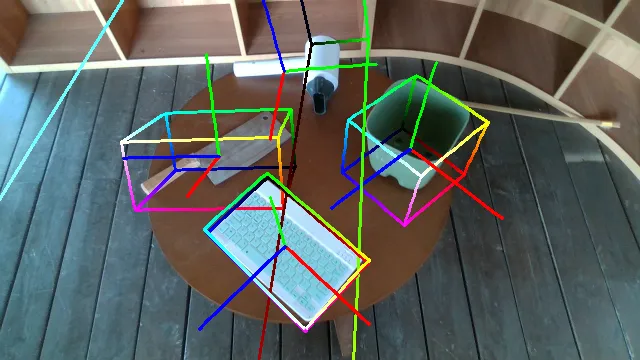
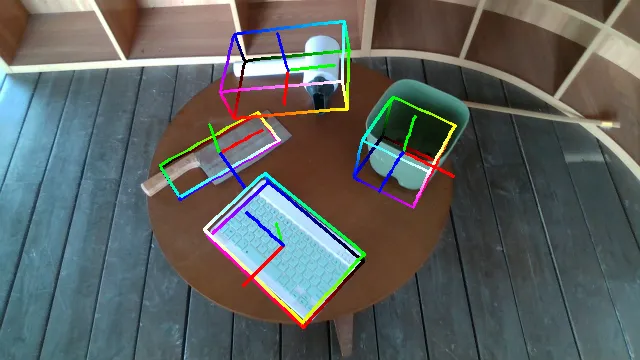







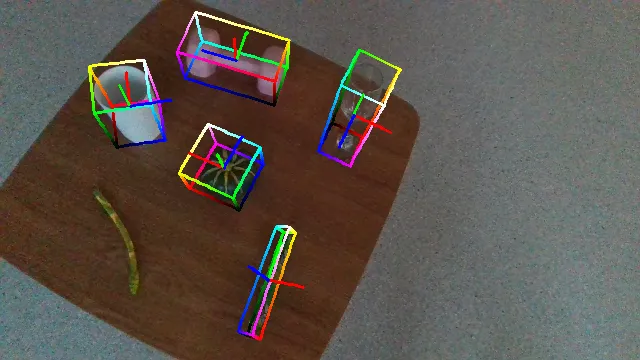

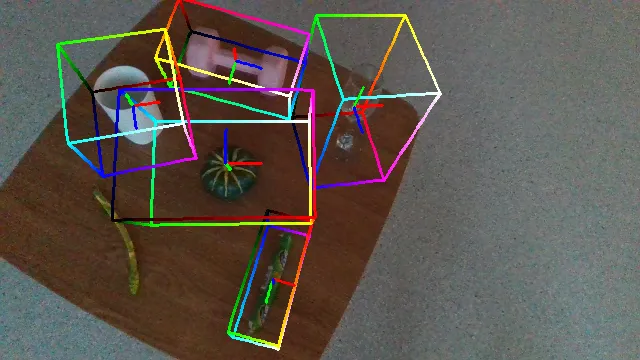


What's More?
Equiping everybody with the best practice of harnessing the Omni6DPose datasets, we provide an official Python library for loading, manipulating and visualizing the datasets. We also provide a quasi-standard model evaluation framework as tutorial. Go ant check it out!
(Note: currently this library hasn't been released yet. Only its generated documentation is available :)