Common UTilities for Omni6DPose
Module: cutoop.
cutoop (pronounced /'kʌtup/ ) is the official package containing convenient
utilities for data preparation and model evaluation over the Omni6DPose
dataset.
Installation & Prerequisites
To enable EXR image reading by OpenCV, you need to install OpenEXR. On Ubuntu you have:
sudo apt-get install openexr
Install via pip
Now you can install this package directly via pip:
pip install cutoop
Install from source
After cloning this repository, you may run pip install . under common folder
(note that the installed package is still named cutoop ).
Evaluation Framework
Here comes a simple framework of model inference and evaulation. Notable APIs used in this simple example are listed below for referencing:
- data_loader.Dataset
- obj_meta.ObjectMetaData.load_json()
- eval_utils.GroundTruth
- eval_utils.DetectMatch
- eval_utils.Metrics.dump_json()
Firstly, after fetching data prefix list using data_loader.Dataset.glob_prefix() , you may want to filter the object annotations in some way:
import cutoop
import numpy as np
from cutoop.data_loader import Dataset
from cutoop.eval_utils import GroundTruth, DetectMatch, DetectOutput
from dataclasses import asdict
# define a helper function to print JSON in a pretty way
def print_json(data):
def round_floats(o):
if isinstance(o, float):
return round(o, 5)
if isinstance(o, dict):
return {k: round_floats(v) for k, v in o.items()}
if isinstance(o, (list, tuple)):
return [round_floats(x) for x in o]
return o
json.dump(round_floats(data), sys.stdout, indent=2)
# Object metadata of SOPE dataset
objmeta = cutoop.obj_meta.ObjectMetaData.load_json(
"../../configs/obj_meta.json"
)
# take this prefix for example
prefix = "../../misc/sample/0000_"
# load RGB color image (in RGB order)
image = Dataset.load_color(prefix + "color.png")
# load object metadata
meta = Dataset.load_meta(prefix + "meta.json")
# load object mask (0 and 255 are both backgrounds)
mask = Dataset.load_mask(prefix + "mask.exr")
# load depth image. 0 and very large values are considered invisible
depth = Dataset.load_depth(prefix + "depth.exr")
depth[depth > 1e5] = 0
# retain objects with at least 32 pixels visible in a reasonable distance
occurs, occur_count = np.unique(np.where(depth == 0, 0, mask), return_counts=True)
occurs = occurs[occur_count > 32]
objects = [obj for obj in meta.objects if obj.is_valid and obj.mask_id in occurs]
After that we can prepare a eval_utils.GroundTruth before the inference process:
gts = []
for obj in objects:
objinfo = objmeta.instance_dict[obj.meta.oid]
gt = GroundTruth(
# object pose relative to camera
gt_affine=obj.pose().to_affine()[None, ...],
# object size under camera space
gt_size=(
np.array(obj.meta.scale) * np.array(objinfo.dimensions)
)[None, ...],
gt_sym_labels=[objinfo.tag.symmetry],
gt_class_labels=np.array([objinfo.class_label]),
# these are optional
image_path=prefix + "color.png",
camera_intrinsics=meta.camera.intrinsics,
)
gts.append(gt)
# Concatenate multiple arrays into one.
gt = GroundTruth.concat(gts)
Inference with ground truth detection
Now you may start the inference process, with filtered objects as inputs. Assume we have a model that can predict correct rotation and translation, but incorrect scales.
np.random.seed(0)
pred_affine = gt.gt_affine
pred_size = gt.gt_size * (0.8 + np.random.rand(*gt.gt_size.shape) * 0.4)
# Now we can collect the prediction results.
# Apart from constructing DetectMatch from GroundTruth, you can also construct
# it directly by filling its members.
result = DetectMatch.from_gt(gt, pred_affine=pred_affine, pred_size=pred_size)
# Calibrate the rotation of pose prediction according to gt symmetry.
result = result.calibrate_rotation()
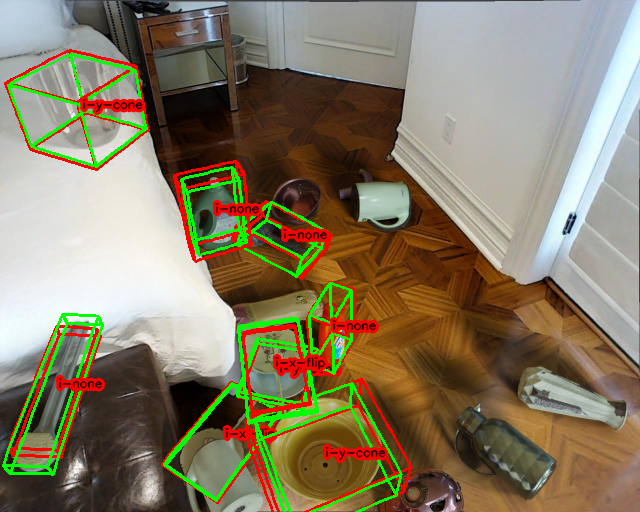
# We can visualize the prediction, which outputs to ``./result.png`` as default.
result.draw_image(path='source/_static/gr_0.png')
# Calculate metrics.
metrics = result.metrics()
print_json(asdict(metrics.class_means))
Inference with detection outputs
Assume we have a detection model that can detect 5 of the objects (after matching). After object detection and matching, before post estimation, you may prepare a eval_utils.DetectOutput . Is ok not to do so, then you’ll have to compose a eval_utils.DetectMatch after pose estimation as a whole.
from collections import Counter
np.random.seed(0)
detect_gt = GroundTruth.concat(gts[:5])
detection = DetectOutput(
gt_affine=detect_gt.gt_affine,
gt_size=detect_gt.gt_size,
gt_sym_labels=detect_gt.gt_sym_labels,
gt_class_labels=detect_gt.gt_class_labels,
image_path=detect_gt.image_path,
camera_intrinsics=detect_gt.camera_intrinsics,
detect_scores=np.random.rand(len(detect_gt)),
gt_n_objects=Counter(gt.gt_class_labels), # pass an iterable to Counter
)
print("total objects:", len(gt))
print("detected objects:", len(detection))
Then we make prediction upon detected objects:
pred_affine = detection.gt_affine
pred_size = detection.gt_size * (
0.8 + np.random.rand(*detection.gt_size.shape) * 0.4
)
# Now we can collect the prediction results and calibrate the rotation.
result = DetectMatch.from_detection(
detection, pred_affine=pred_affine, pred_size=pred_size
)
result = result.calibrate_rotation()
The bottleneck of metrics computation is 3D bounding box IoU. Here we introduce a trick: you may cache the result of criterion and then pass it to the metrics method if you somehow need to compute metrics for different settings multiple times.
BTW, eval_utils.Metrics.dump_json() can be used to save metrics to JSON file.
criterion = result.criterion() # you may use pickle to cache it
metrics = result.metrics(
iou_thresholds=[0.25, 0.50, 0.75],
pose_thresholds=[(5, 2), (5, 5), (10, 2), (10, 5)],
criterion=criterion
)
print_json(asdict(metrics.class_means))